|
Email: byp215[at]gmail.com Google Scholar Github I am Yunpeng Bai, a Ph.D. student in Computer Science at UT Austin, advised by Qixing Huang. My interests lie in using computer algorithms to create visually striking content, with a recent focus on 3D foundational models and 3D visual content generation. I previously graduated with a master's degree from Tsinghua University, where I was an outstanding graduate. During my time at Tsinghua, I had the opportunity to intern extensively at Tencent AI Lab, where I gained significant practical experience and had the privilege of working with several distinguished researchers, including Xuan Wang, Yong Zhang, Xintao Wang and Yan-Pei Cao. I also work closely with Prof. Chao Dong. |

|
|
|

|
Yunpeng Bai, Shaoheng Fang, Chaohui Yu, Fan Wang, Qixing Huang The Thirty-Ninth Annual Conference on Neural Information Processing Systems (NeurIPS), 2025, [PDF] [Project Page] In this work, we introduce geometric regularization losses into video generation by augmenting latent diffusion models with per-frame depth prediction. We adopted depth as the geometric representation because of the great progress in depth prediction and its compatibility with image-based latent encoders. Specifically, to enforce structural consistency over time, we propose a multi-view geometric loss that aligns the predicted depth maps across frames within a shared 3D coordinate system. |
|
Shuzhao Xie*, Jiahang Liu*, Weixiang Zhang, Shijia Ge, Sicheng Pan, Chen Tang, Yunpeng Bai, Cong Zhang, Xiaoyi Fan, Zhi Wang *Equal contribution ACM Multimedia (MM), 2025, Best Paper Candidate, [PDF] [Project Page] [Code] |

|
Yunpeng Bai, Qixing Huang International Conference on Computer Vision (ICCV), 2025, [PDF] [Code] [Project Page] We propose an efficient MDE approach named FiffDepth. The key feature of FiffDepth is its use of diffusion priors. It transforms diffusion-based image generators into a feed-forward architecture for detailed depth estimation. FiffDepth preserves key generative features and integrates the strong generalization capabilities of models like DINOv2. Through benchmark evaluations, we demonstrate that FiffDepth achieves exceptional accuracy, stability, and fine-grained detail, offering significant improvements in MDE performance against state-of-the-art MDE approaches. |
|
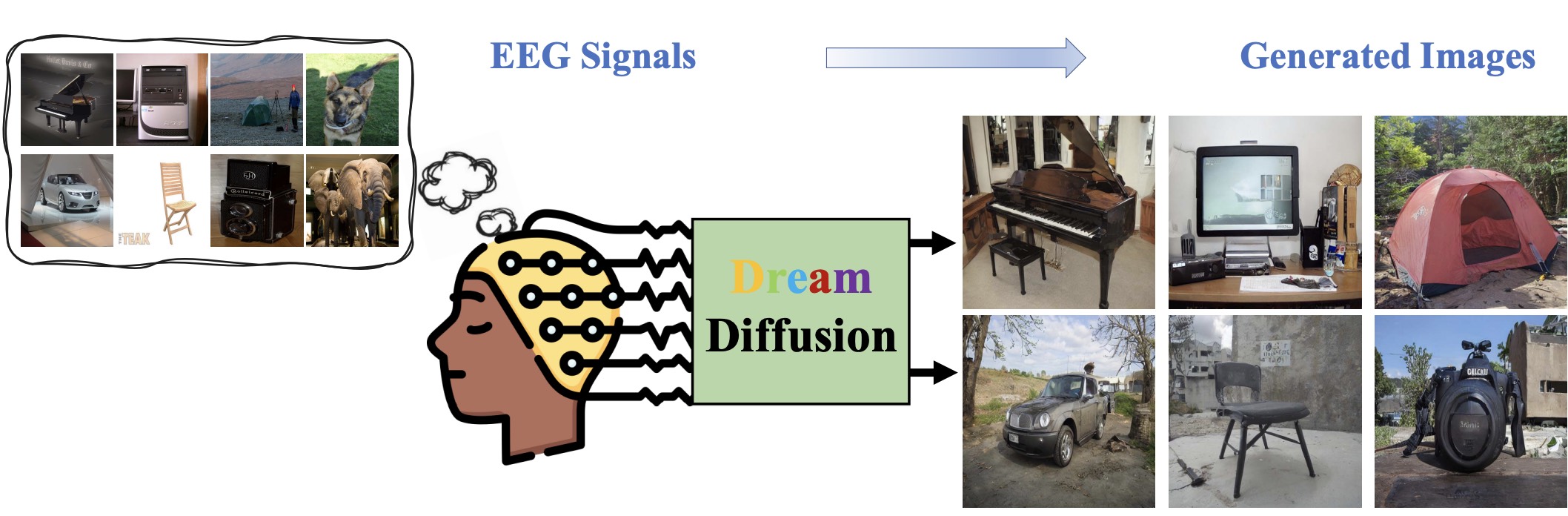
Yunpeng Bai, Xintao Wang, Yan-Pei Cao, Yixiao Ge, Chun Yuan, Ying Shan European Conference on Computer Vision (ECCV), 2024, [PDF] [Code] This paper introduces DreamDiffusion, the first method for generating high-quality images directly from brain electroencephalogram (EEG) signals, without the need to translate thoughts into text. |
|
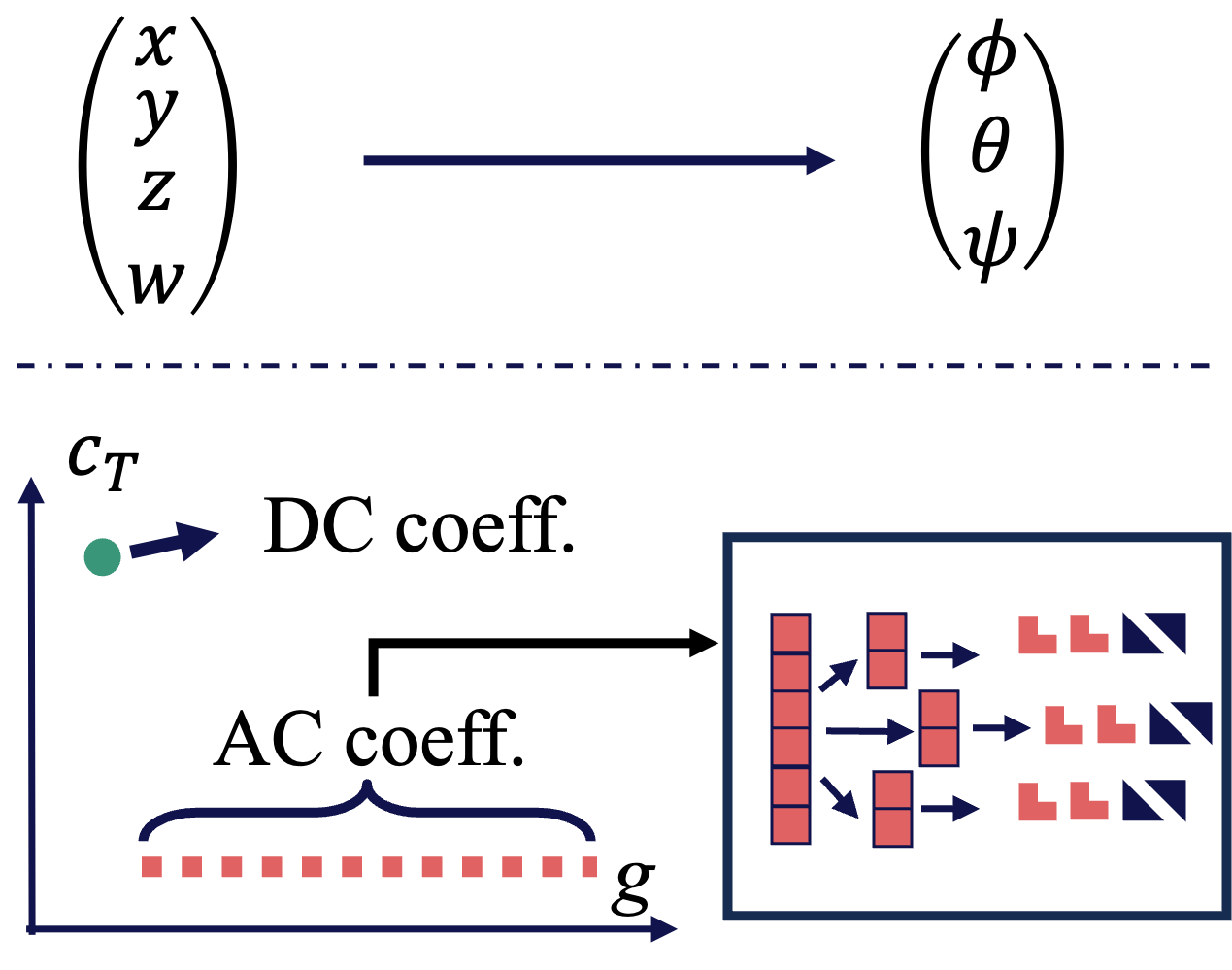
Shuzhao Xie, Weixiang Zhang, Chen Tang, Yunpeng Bai, Rongwei Lu, Shijia Ge, Zhi Wang European Conference on Computer Vision (ECCV), 2024, [PDF] [Code] [Project] In this paper, we propose MesonGS, a codec for post-training compression of 3D Gaussians. Initially, we introduce a measurement criterion that considers both view-dependent and view-independent factors to assess the impact of each Gaussian point on the rendering output, enabling the removal of insignificant points. Subsequently, we decrease the entropy of attributes through two transformations that complement subsequent entropy coding techniques to enhance the file compression rate. |
|
|
Yunpeng Bai, Yanbo Fan, Xuan Wang, Yong Zhang, Jingxiang Sun, Chun Yuan, Ying Shan IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2023, [PDF] [Code] In this work, we propose a new method for NeRF-based facial avatar reconstruction that utilizes 3D-aware generative prior. Different from existing works that depend on a conditional deformation field for dynamic modeling, we propose to learn a personalized generative prior, which is formulated as a local and low dimensional subspace in the latent space of 3D-GAN. |

|
Yunpeng Bai, Cairong Wang, Shuzhao Xie, Chao Dong, Chun Yuan, Zhi Wang IEEE Transactions on Visualization and Computer Graphics (TVCG) 2025, [PDF] [Code] In this work, we design an effective framework that allows the user to control the restoration process of degraded images with text descriptions. We use the text-image feature compatibility of the CLIP to alleviate the difficulty of fusing text and image features. Our framework can be used for various image restoration tasks, including image inpainting, image super-resolution, and image colorization. |

|
Wangbo Yu, Yanbo Fan, Yong Zhang, Xuan Wang, Fei Yin, Yunpeng Bai, Yan-Pei Cao, Ying Shan, Yang Wu, Zhongqian Sun, Baoyuan Wu SIGGRAPH (Conference Track) 2023, [PDF] [Code] We propose a one-shot 3D facial avatar reconstruction framework, which only requires a single source image to reconstruct high-fidelity 3D facial avatar, by leveraging the rich generative prior of 3D GAN and developing an efficient encoder-decoder network. |
|
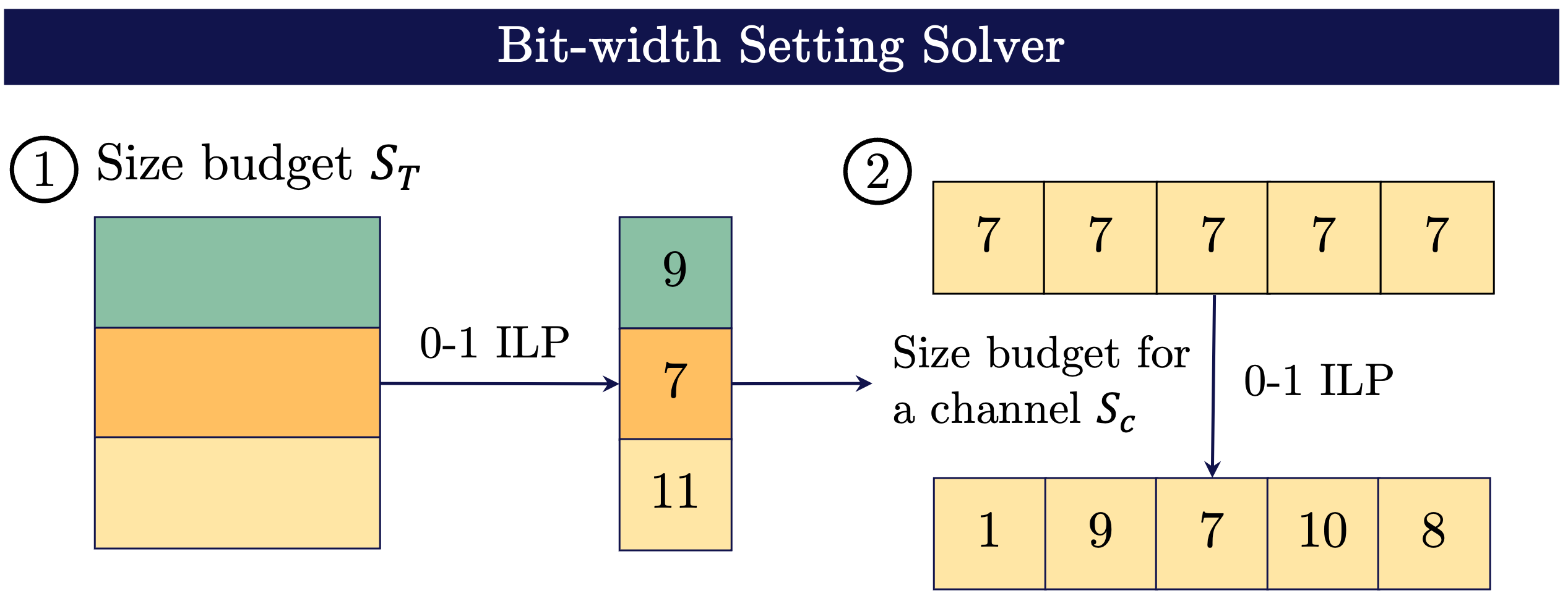
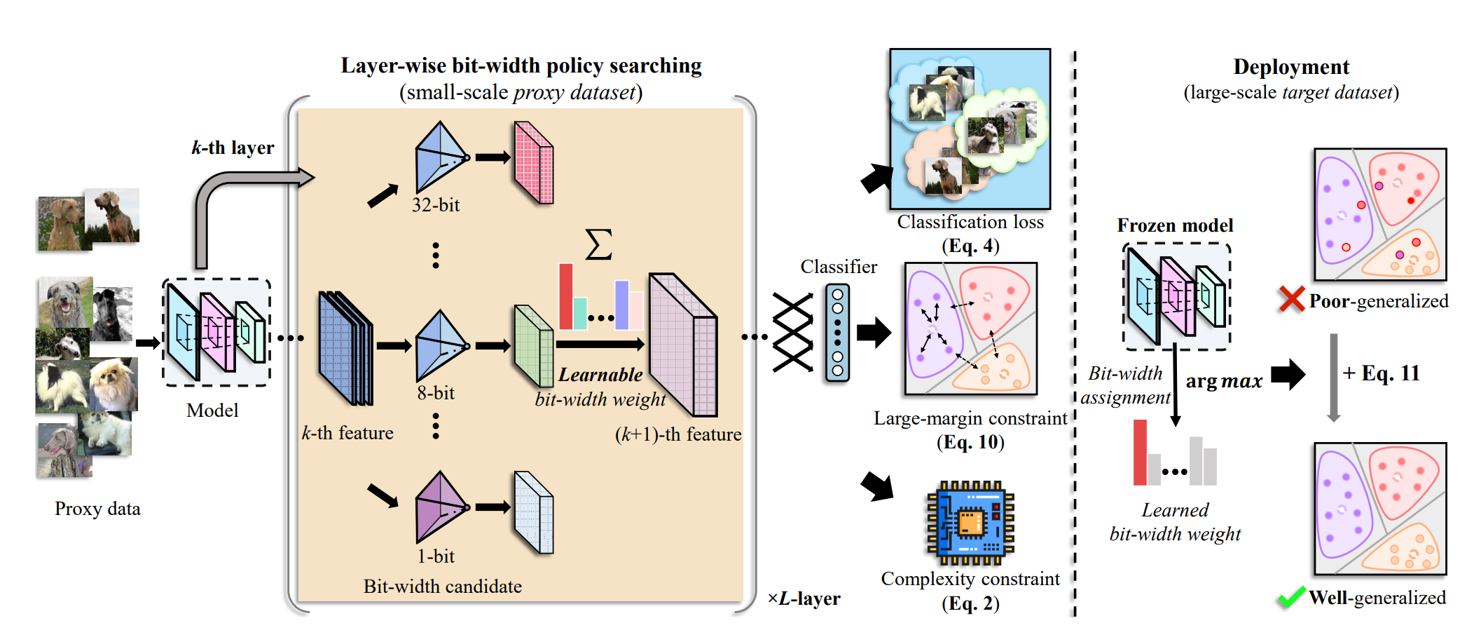
Chen Tang, Kai Ouyang, Zenghao Chai, Yunpeng Bai, Yuan Meng, Zhi Wang, Wenwu Zhu ACM International Conference on Multimedia (ACM MM) 2023, [PDF] In this paper, we propose to search the effective MPQ policy by using a small proxy dataset for the model trained on a large-scale one. It breaks the routine that requires a consistent dataset at model training and MPQ policy search time, which can improve the MPQ searching efficiency significantly. |
|
|
Yunpeng Bai, Chao Dong, Cairong Wang, Chun Yuan IEEE International Conference on Image Processing (ICIP) 2023, [PDF] We study how to represent a video with implicit neural representations (INRs). Classical INRs methods generally utilize MLPs to map input coordinates to output pixels. While some recent works have tried to directly reconstruct the whole image with CNNs. However, we argue that both the above pixel-wise and image-wise strategies are not favorable to video data. Instead, we propose a patch-wise solution, PS-NeRV, which represents videos as a function of patches and the corresponding patch coordinate. It naturally inherits the advantages of image-wise methods, and achieves excellent reconstruction performance with fast decoding speed. |

|
Yunpeng Bai, Chao Dong, Zenghao Chai, Andong Wang, Zhengzhuo Xu, Chun Yuan European Conference on Computer Vision (ECCV), 2022, [PDF] [Code] We propose Semantic-Sparse Colorization Network (SSCN) to transfer both the global image style and detailed semantic-related colors to the gray-scale image in a coarse-to-fine manner. Our network can perfectly balance the global and local colors while alleviating the ambiguous matching problem. |

|
Zenghao Chai, Zhengzhuo Xu, Yunpeng Bai, Zhihui Lin, Chun Yuan IEEE International Conference on Multimedia and Expo (ICME) 2022, [PDF] [Code] To tackle the increasing ambiguity during forecasting, we design CMS-LSTM to focus on context correlations and multi-scale spatiotemporal flow with details on fine-grained locals, containing two elaborate designed blocks: Context Embedding (CE) and Spatiotemporal Expression (SE) blocks. CE is designed for abundant context interactions, while SE focuses on multi-scale spatiotemporal expression in hidden states. |

|
Junjie Cao, Hairui Zhu, Yunpeng Bai, Jun Zhou, Jinshan Pan, Zhixun Su IEEE Transactions on Industrial Electronics (TIE), 2022, 69(1), 921-929, [PDF] [Code] We propose a simple deep network to estimate the normal vector based on a latent tangent space representation learned in the network. We call the network tangent represent learning network (TRNet). For each query point, the tangent space representation is a set of latent points spanning the tangent plane of it. The representation is generated using only the coordinates of its neighbors and regularized by a differentiable random sample consensus like component, which makes TRNet more compact and effective for normal estimation. |
|
The website template was adapted from Jon Barron. |